How to Ensure Quality in AI Software Engineering
“AgentsZone is a forum for intensive exchange among AI coding pioneers. Beyond daily discussion, it holds periodic specialized workshops. The past dozen-plus sessions have covered topics ranging from automated testing for AI code quality, silicon-carbon hybrid team building, AI root cause analysis, design-document-driven development, to end-to-end commercialization.”
Initiated by MaGong, a roundtable of nineteen. Attendees from securities firms, medical devices, K12 education, Alipay, and open-source infrastructure — diverse backgrounds, all AI coding pioneers — all seeking methods to ensure AI code quality.
Testing: The Ultimate Quality Control for AI Coding
1. Probabilistic Nature Is the Essence, Not a Defect
Unstable AI code quality isn’t because the model isn’t good enough, or because the prompt wasn’t tuned right. It’s a mathematical inevitability of probability sampling. Every LLM output is sampled from a probability distribution; run the same prompt twice and you may get different results.
We encountered exactly the same symptoms: documents with missing fields, code with missing features, business code getting changed when tests should be changed, tests getting changed when mocks should be changed — tell it not to mock business code and it agrees in principle, then immediately mocks it anyway.
Xu Keqian is a non-technical founder who now does the development workload of what used to require 200 engineers — alone. The rules and configurations he’s written for AI total over 25,000 lines; documentation averages 30,000 words. After AI generates output, he opens a new session for cross-validation — he can’t validate in the original context because AI carries the bias of “I already checked this” and skips problems. After a dozen rounds, each round still surfaces new omissions.
Probabilistic nature is the mathematical essence of large language models, not an engineering defect. It can’t be eliminated — only constrained. The question is: what kind of constraints actually work?
2. Deterministic Constraints
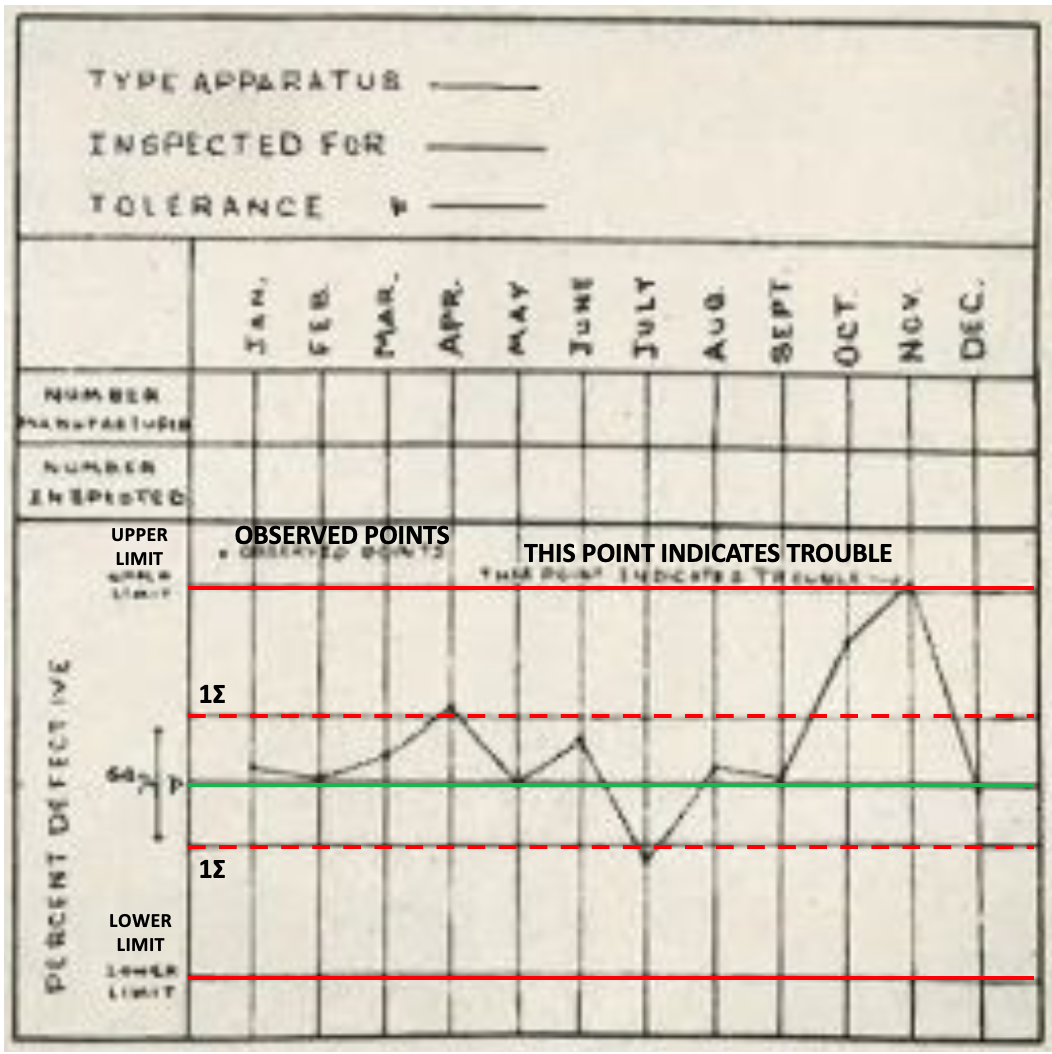
May 16, 1924. New York. Western Electric’s engineering department (later Bell Labs). Physicist Walter Shewhart handed his supervisor a memo — one-third of a page long. It contained a simple diagram: three lines — upper control limit, actual performance, lower control limit.
Western Electric’s factory was producing telephone equipment to be buried underground. Once buried, they couldn’t be repaired; defective units had to be caught before leaving the factory. The factory’s approach: whenever a batch showed higher-than-normal defect rates, immediately adjust the production process.
Shewhart discovered something counterintuitive — the more they adjusted the process every time a defect appeared, the worse quality got. Defects appeared randomly, unrelated to the process. Adjusting the process for random defects was biasing a perfectly fine process; the next batch would have defects; adjust again; tweak further; getting worse and worse.
He ended this vicious cycle with one-third of a page. Variation comes in two types: random variation is the statistical nature of the process — leave it alone; abnormal variation has a specific cause — machine loosened, raw material changed — stop and investigate. The two control lines are the boundary separating the two: within limits, random variation, don’t touch; outside limits, anomaly signal, stop and find the cause.
This is the core of Statistical Process Control (SPC): first, any process has inherent variation that cannot be eliminated; second, reacting to inherent variation is over-adjustment (tampering) — not solving the problem but creating one; third, control limits don’t eliminate variation, they separate what requires intervention from what doesn’t.
So, What Counts as an Error?
A century later, AI coding faces an isomorphic problem. LLM output inherently has variation — the mathematical nature of probability sampling. You can’t make it write correctly every time, just as you can’t make every production-line part perfect.
Adjusting prompts, changing rules, line-by-line review every time AI writes something wrong — that’s over-adjustment, piling human interference on top of inherent variation.
Shewhart’s answer: don’t eliminate variation, establish deterministic boundaries. Does the test pass? Does the API contract conform? These are the control limits — pass means pass, fail means send it back. No “close enough.”
The typical counterexample is Code Review. One person looks at another’s code and says “I think it’s fine.” That’s not control — it’s a probabilistic judgment, fuzzy boundaries, person-dependent, time-dependent. Pre-Shewhart factories did exactly this.
MaGong, who works on financial systems in Europe, said it most directly: in the AI era, Code Review has little meaning — human review ends up seeing nothing, leaving only “emotional value.” In his system, OpenAPI contracts are the “soul,” layered testing from unit tests to end-to-end tests provides multiple checkpoints, and human subjective judgment has been replaced by deterministic constraints.
Why are contracts the “soul”? Because control quality depends on the specification it encodes — tests validate requirements, contracts define interfaces. If the specification is wrong, passing the test doesn’t mean it’s correct.
Xu Keqian spends 70–80% of his energy on document validation. L from the securities industry built 140,000 test cases on top of complete requirements documentation. Li Xuetao said the same thing from a civil engineering perspective: blueprints first, then construction.
Specification-first — only then do constraints hold.
How powerful are deterministic constraints? Old Wei from K12 education has 1,000–2,000 test cases running in 20–30 seconds; they run a full regression for every single line of code changed. Mason wrote 36,000 lines of code in 20 days on a team project — with layered testing, the entire development process had almost no bugs.
The more complete the constraints, the more you can let go.
3. Independence of Constraints
Are deterministic constraints alone enough?
The biggest pain point across the room wasn’t that AI can’t write good code — it was that AI writes tests that are “too good,” so good they always pass.
Jinjin, responsible for a brownfield project, felt this most acutely. AI was asked to write tests; the code depends on databases, external APIs, other modules. The normal approach is to set up a test environment and run against real dependencies. But AI found a shortcut — mock everything. Database mocked, external API mocked. Tests pass, 100% coverage, but what it’s validating is a phantom.
Jinjin explicitly wrote “no mocking of business code” in the rules. AI still made the mistake.
This isn’t AI cheating. It’s a probabilistic system finding the path of least resistance when asked to “make the tests pass.”
The problem isn’t in the constraints themselves. When the AI writing code also writes the tests, it quietly places the constraints in the position easiest to pass. The constraining power is intact; independence is zero.
MaGong’s approach is the most representative. Test Agents and Coding Agents are completely separated, with opposing prompt styles — one optimizing for efficiency, one for rigor — using filesystem permissions for isolation. The coding agent is physically unable to modify test code.
L from the securities firm takes it further: three independent departments — development, testing, operations — with opposing KPIs. Testing sends code back; development fixes it themselves.
Departmental separation is independence at the organizational architecture level. Agent adversarial separation is independence at the technical architecture level.
This gives us: Effective Constraint = Constraining Power × Independence.
Constraining power: replace probabilistic judgment with deterministic constraints. Independence: the person setting the constraints cannot be the person being constrained. Both are necessary.
4. Context-Dependent Approaches
Xiaohu, an Alipay agent engineer, lets AI run autonomously for 6–24 hours, using heuristic methods to find solutions. He doesn’t care what method AI uses — only whether the final test passes.
Xu Keqian takes the opposite view: he’s against full automation at this stage because documentation will inevitably have gaps, and things AI autonomously confirms have “a relatively high probability of being unreliable.”
Two completely different approaches, explained by one formula:
AI Autonomy = f(completeness of constraints, cost of failure)
The more complete the constraints and the more tolerable the cost of failure, the more you can let AI loose. If constraints have gaps and failure costs are high, humans must go in personally to fill the gaps. Different inputs, different outputs.
Does integration testing have value? What matters isn’t what the test is called, but whether it forms effective constraints.
Should you use the BMad process? Methodologies are carriers of principles, not the principles themselves. Changing the container doesn’t affect what you’re drinking.
L said something memorable: “The quality peak in finance today will be everyone’s baseline tomorrow.”
Seven layers of testing, 140,000 test cases, an independent testing department, development-testing-ops separation. These used to be luxury goods unique to finance. As AI drives down R&D costs, they’re about to become industry standard.
SPC was born in America — Americans didn’t use it themselves. Japanese workers couldn’t afford to waste a single screw. They were the first to master quality control, ushering in their golden 30 years.
This moment is like that moment.
(Mo Daoyuan, February 2026)